 |
한 권으로 끝내는 실전 LLM 파인튜닝 -  강다솔 지음/위키북스 |
04. 효율적인 파라미터 튜닝 기법 (PEFT)
70B Llama 3 모델을 16bits로 로드한다면 무려 140GB VRAM이 필요하다고 한다. 최근 연구는 대규모 모델을 더 적은 VRAM을 사용해 로드할 수 있는 방법에 초점을 맞추고 있는데 주요 기술 중 하나가 바로 양자화(quantization)이다.
양자화의 이해
딥러닝 모델을 사용하다 보면 FP32, BF16, FP16 같은 torch.dtype 설정을 하게 되는데 이는 모두 부동소수점 방식을 사용해 숫자를 표현하는 데이터 타입이다. 아래 이미지는 FP32(Float 32-bit)와 FP16(Float 16-bit)로 원주율을 표현하는 예시다.

가수(fraction/mantissa) 부분 중심으로 더 많은 비트를 사용할수록 더 정밀한 표현이 가능하다는 것을 보여준다. 특히 0에 가까운 값들을 표현할 때 더 높은 정밀도를 얻을 수 있다는 사실을 알 수 있다. 추가로 알아볼 부분이 있는데 FP32에서 FP16으로 변환할 때는 표현할 수 있는 수의 범위가 줄어들지만 BF16으로 변환할 때는 범위가 그대로 유지된다. 이는 가수 부분은 축소(23비트->7비트)되지만 지수(Exponent) 부분은 8비트를 유지하기 때문이다. 즉 BF16은 숫자를 정밀하게 표현하는 능력은 일부 포기하는 대신, 매우 크거나 작은 숫자도 표현할 수 있게 한 것이다.


양자화는 컴퓨터가 다루는 숫자의 표현 방식을 조정하는 기술이다. 이를 통해 메모리 사용량을 줄이고 연산 속도를 높인다. 양자화에는 크게 두 가지 방법이 있는데 첫 번째는 대칭 양자화(Symmetric Quantization)다. 이 방법은 0을 중심으로 양쪽으로 동일하게 숫자의 범위를 줄인다. 구현이 간단하고 이해하기 쉽다. 두 번째는 비대칭 양자화(asymmetric Quantization)다. 이 방법은 데이터의 분포에 따라 한쪽으로 더 치우치게 숫자의 범위를 조절한다. 이 방법은 데이터의 특성을 더 잘 반영할 수 있지만, 구현이 좀 더 복잡하다고 한다. 다음으로 양자화 오류에 대해 알아보겠다. 양자화 오류는 실숫값을 정수로 변환하는 과정에서 불가피하게 발생하는 정보의 손실을 말한다.
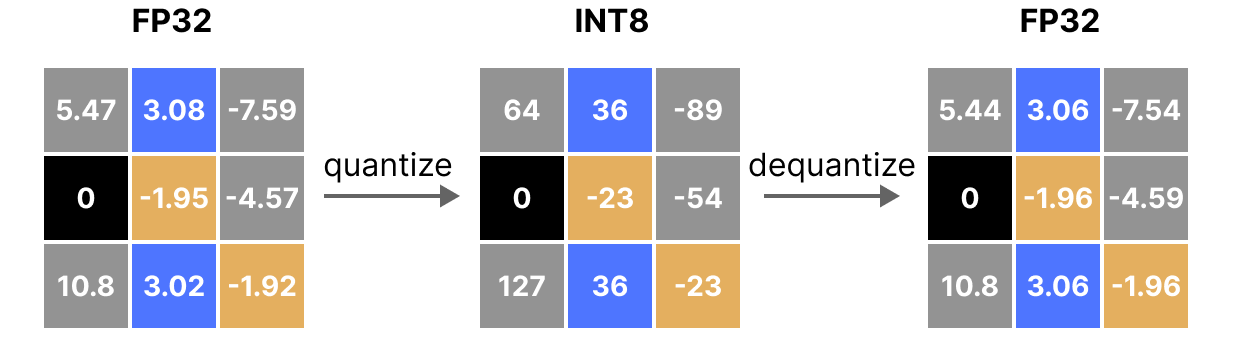
위 그림은 FP32 데이터를 정수형(INT8)로 변환하는 양자화 과정과 이를 다시 FP32로 되돌리는 역양자화 과정을 표한한 것이다. 이 과정을 통해 데이터가 원래의 형태와 유사한 상태로 복원되지만 일부 정보가 손실될 수 있다.
런팟 환경 설정
RunPod - The Cloud Built for AI
Develop, train, and scale AI models in one cloud. Spin up on-demand GPUs with GPU Cloud, scale ML inference with Serverless.
www.runpod.io
이번 실습도 GPU 클라우스 서비스인 런팟에서 진행한다. 실습을 진행할 런팟 사양은 H100(VRAM 80GB) 1개, Container/Volume Disk 각 400GB 다.
데이터셋 준비
아래와 같이 필요한 라이브러리를 설치하고 임포트한 이후에 적용 결과까지 확인한다.
%%capture
!pip install transformers bitsandbytes datasets sentencepiece accelerate trl peft flash-attn wandb openai pqdmprint(f"PyTorch version : {torch.__version__}")
print(f"Transformers version : {transformers.__version__}")
print(f"TRL version : {trl.__version__}")
print(f"CUDA available : {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"CUDA version : {torch.version.cuda}")PyTorch version : 2.3.1+cu121
Transformers version : 4.42.4
TRL version : 0.9.6
CUDA available : True
CUDA version : 12.1위에서 TRL(Transfomer Rinforcement Learning)는 강화 학습을 통해 언어 모델을 파인튜닝하는 데 사용되는 라이브러리다. 이번 실습에 사용할 데이터셋은 텍스트와 SQL 쿼리 필드로 구성돼 있다.
https://huggingface.co/datasets/daje/kotext-to-sql-v1
daje/kotext-to-sql-v1 · Datasets at Hugging Face
Below are sql tables schemas paired with instruction that describes a task. Using valid SQLite, write a response that appropriately completes the request for the provided tables. ### Instruction: Users with highest reputation both in SO and Math ( geometri
huggingface.co

원본 데이터셋의 영어로 된 instruction 필드뿐이었는데 gpt-4o-mini 모델을 이용해서 한국어로 번역한 필드(ko_instruction)를 추가했다고 한다. 데이터셋을 로드하고 'ko_instruction', 'input', 'response' 세 가지 요소의 길이를 더해 'total_length'라는 새로운 필드를 추가한다. total_length의 값에 따라 데이터를 세 개의 난이도(easy, moderate, difficult)로 분류한다.
def add_length_column(dataset):
df = dataset.to_pandas()
df["total_length"] = 0
for column_name in ["ko_instruction", "input", "response"]:
num_words = df[column_name].astype(str).str.split().apply(len)
df["total_length"] += num_words
return df
df = add_length_column(dataset["train"])
def filter_by_total_length(df, difficulty, number_of_samples):
if difficulty == "easy":
return df[df["total_length"].between(10, 100)].iloc[:number_of_samples]
elif difficulty == "moderate":
return df[df["total_length"].between(101, 300)].iloc[:number_of_samples]
elif difficulty == "difficult":
return df[df["total_length"].between(301, 1000)].iloc[:number_of_samples]전체 데이터셋의 규모는 약 26만 건으로 상당히 큰 편이라 학습에만 약 7~9시간이 소요된다고 한다. 따라서 일부만을 무작위로 추출하는 랜덤 샘플링 방식으로 학습을 진행한다.
easy = filter_by_total_length(df, "easy", 5000)
medium = filter_by_total_length(df, "moderate", 5000)
hard = filter_by_total_length(df, "difficult", 5000)
dataset = pd.concat([easy, medium, hard])
dataset = dataset.sample(frac=1)
dataset = Dataset.from_pandas(dataset)
easy.shape, medium.shape, hard.shape, dataset.shape위의 코드와 같이 easy, moderate, difficult 세 가지 난이도에 대해 각각 5,000개의 샘플을 추출한다. 추출한 데이터는 pd.concat 함수로 다시 하나의 데이터프레임으로 결합한다. 이어서 데이터 무작위성 확보를 위해 sample 함수를 사용해 전체 데이터를 섞는다. 마지막으로 Dataset.from_pandas 함수를 사용해서 pandas 데이터프레임을 허깅페이스 Dataset 형식으로 변환한다. 허깅페이스 Dataset 형식은 모델 학습에 최적화돼 있어서 데이터 로딩과 처리를 효율적으로 할 수 있다고 한다.
def get_chat_format(element):
system_prompt = "You are a helpful programmer assistant that excels at SQL."
user_prompt = "Task: {ko_instruction}\nSQL table: {input}\nSQL query: "
return {
"messages": [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt.format_map(element)},
{"role": "assistant", "content": element["response"]+tokenizer.eos_token},
]
}
# 중간 생략..
dataset = dataset.map(get_chat_format, remove_columns=dataset.features, batched=False)
dataset = dataset.train_test_split(test_size=0.05)
dataset["train"].to_json("train_dataset.json", orient="records")
dataset["test"].to_json("test_dataset.json", orient="records")이어서 위의 코드와 같이 데이터셋을 STF Trainer에 적합한 대화 형식으로 변환한다. get_chat_format 함수는 각 데이터 항목을 시스템 프롬프트, 사용자 프롬프트, 어시스턴트 응답을 포함한 대화 형식으로 변환한다. dataset.map 함수를 호출해서 데이터셋 전체에 이를 적용한다. 이 과정에서 원래 데이터셋의 특성(features)은 제거된다고 한다. 변환된 데이터 셋은 95:5 비율로 훈련용과 테스트용으로 분할한다. 분할된 데이터는 각각 json 파일로 저장한다.
양자화 파라미터 설정
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)BitsAndBytesConfig를 사용해서 양자화 파라미터 설정을 진행한다. 모델을 4비트 정밀도로 로드하고, 이중 양자화 기법을 사용해서 정확도 손실을 줄인다. 그리고 다양한 양자화 방식 중 정규화된 부동 소수점 4비트 양자화를 의미하는 'nf4'를 선택한다.
모델 준비
아래와 같이 실습에 사용할 기본 모델을 선택해서 불러온다.
model_id = "allganize/Llama-3-Alpha-Ko-8B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
quantization_config=bnb_config
)한국어에 특화된 Llama 3 모델인 'allganize/Llama-3-Alpha-Ko-8B-Instruct'를 사용한다. 13일 차는 여기까지다. 이어지는 14일 차 에서는 학습 파라미터 설정부터 시작해서 QLoRA 파인튜닝의 나머지 부분을 다룬다. 끝.
'개발 > AI' 카테고리의 다른 글
| [Day15] LLM 스터디 1기 - vLLM 서빙 (6) | 2025.01.30 |
|---|---|
| [Day14] LLM 스터디 1기 - 효율적인 파라미터 튜닝(QLoRA 튜닝 실습) (0) | 2025.01.29 |
| [Day12] LLM 스터디 1기 - 효율적인 파라미터 튜닝(LoRA) #2 (1) | 2025.01.23 |
| [Day11] LLM 스터디 1기 - 효율적인 파라미터 튜닝(LoRA) #1 (0) | 2025.01.22 |
| [Day10] LLM 스터디 1기 - 다중 GPU Llama3 파인튜닝 #1 (1) | 2025.01.20 |



