 |
한 권으로 끝내는 실전 LLM 파인튜닝 -  강다솔 지음/위키북스 |
05. vLLM을 활용한 서빙
드디어 마지막 15일 차다. 학습된 모델을 실제 서비스에 적용하는 과정을 실습한다. 앞에서 LLM을 이용해서 문장을 생성할 때 시간이 꽤 오래 걸렸다. 실제 서비스 단계에서는 사용자 경험을 고려해야 하는데 LLM의 추론 속도가 큰 영향을 미친다. vLLM은 이러한 추론 속도 문제를 해결하기 위한 도구로, 페이지드 어텐션(Paged Attention)이라는 기술을 사용한다. 책에 따로 언급되지 않았지만 관련 논문은 https://arxiv.org/pdf/2309.06180로 보인다.
페이지드 어텐션 원리
페이지드 어텐션 시스템은 'Logical KV Cache blocks', 'Block table', 'Physical KV blocks' 세 가지 주요 구성 요소로 이뤄져 있다. 이러한 구조는 마치 컴퓨터의 가상 메모리 시스템과 유사하게 제한된 자원을 효율적으로 관리할 수 있게 해 준다. 특히 Logical KV Cache blocks, Physical KV blocks 둘 다 고정 크기 블록으로 동적 메모리 할당으로 인한 오버헤드를 줄여 준다.

위의 gif 이미지는 프롬프트가 처리되어 Logical KV Cache blocks에 저장되고, Block table에 매핑 정보를 기록되면서 Physical KV blocks에 데이터가 저장되는 방식이 작동하는 과정을 보여준다. LLM 추론에 페이지드 어텐션 방법을 적용하면 동일한 양의 메모리로 훨씬 많은 양의 데이터를 처리할 수 있다.
vLLM 사용 방법
vLLM을 사용하는 방법을 알아보는 이번 실습은 런팟이 아닌 코랩 환경에서 진행한다. 먼저 터미널에서 openai와 vllm을 설치한다.
pip install openai vllm이어서 아래와 같이 필요한 라이브러리들을 불러오고 LLM 클래스의 인스턴스를 생성한다. 이번 실습에 사용할 모델은 'daje/meta-llama3.1-8B-qna-koalpaca-v1.1'으로 저자가 미리 허깅페이스에 업로드했다고 한다.
import openai
from vllm import LLM, SamplingParams
import huggingface_hub
huggingface_hub.login(token="Your_Huggingface_Token")
llm = LLM(model="daje/meta-llama3.1-8B-qna-koalpaca-v1.1")모델 로딩이 완료되면 아래와 같이 테스트를 진행한다.
prompts = [
"안녕 내 이름은",
"한국의 대통령은 ",
"대한민국의 수도는 현재",
"AI의 미래는",
]
sampling_params = SamplingParams(temperature=0.9, top_p=0.95, max_tokens=20)
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")텍스트 생성 매개변수 중 temperature 0.9는 비교적 높은 값으로 이는 모델이 더 창의적이고 다양한 응답을 생성하도록 유도한다. 이 값이 낮으면 예측 가능하고 안전한 응답을 주로 생성한다. 반대로 이 값이 높으면 더 독창적이고 때로는 예상치 못한 응답을 만들어 낸다. 실행 결과는 아래와 같다.
Prompt: '안녕 내 이름은', Generated text: ' 이혜영입니다. 제가 오늘 첫 블로그를 작성하는데,예전 TV에서'
Prompt: '한국의 대통령은 ', Generated text: '5년마다 선거를 하지만, 임기를 중도에서 조기 폐지할 수도 있습니다.'
Prompt: '대한민국의 수도는 현재', Generated text: ' 서울인데, 이전에 다른 지역에서 수도가 배정되었던 적이 있을까요?'
Prompt: 'AI의 미래는', Generated text: ' 어떻게 될까요? 인류에게 미치는 영향은 무엇인가요?'
LLaMA3 생성 속도 가속화
런팟의 Serverless 기능을 이용하면 모델을 24시간 가동 상태로 유지할 수 있고, 필요에 따라 리소스를 유연하게 조절할 수 있다.
https://www.runpod.io/console/serverless
https://www.runpod.io/console/serverless
www.runpod.io
아래 이미지와 같이 왼쪽 탭에서 'Serverless'를 클릭하고 Quick Deploy 섹션에서 Severless vLLM 항목을 선택, Configure 버튼을 클릭한다.

이후 (대부분 기본 값으로) 적절히 설정 값을 채워 넣는다. 중간에 HuggingFace Model을 입력하는 필드가 나오는데 'daje/meta-llama3.1-8B-qna-koalpaca-v1.1'를 입력하면 된다. 또 Worker를 설정하는 단계가 있는데 이는 AI 모델을 실행하고 요청을 처리하는 개별 작업 단위를 의미한다. Worker 설정을 통해 동시에 처리할 수 있는 요청의 수와 리소스 활용도를 조절할 수 있다. 여기서 GPU는 H100, VRAM 80GB 정도로 선택해야 이후 실습에 무리가 없다.

설정을 완료하고 delpoy 하면 위와 같이 Serverless 메뉴 하위에 항목이 하나 추가되는 것을 확인할 수 있다. 이제 아래 코드와 같이 모델을 구동시키고 작동을 확인한다.
import os
from openai import OpenAI
os.environ["RUNPOD_API_KEY"] = "your_runpod_api_key"
runpod_url = "runpod_url_key"
openai_api_base = f"https://api.runpod.ai/v2/{runpod_url}/openai/v1"
client = OpenAI(
api_key=os.environ["RUNPOD_API_KEY"],
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="daje/meta-llama3.1-8B-qna-koalpaca-v1.1",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "대한민국의 수도는 현재"},
]
)
chat_response.choices[0].message.contentrunpod_url 변수에 할당되는 your_runpod_api_key 부분은 런팟의 Settings 메뉴에서 API 키를 생성하고 이 값을 넣으면 된다. openai_api_base 변수의 {runpod_url} 값은 런팟의 Severless 메뉴에 deploy된 항목에 표시되는 https://api.runpod.ai/v2/ 이후의 고유 값으로 교체한다. 참고로 이 코드는 OpenAPI 라이브러리를 사용하지만 client.chat.completions.create 메서드를 사용해 Open API와 유사한 방식으로 다른 서비스를 호출한다. 이 방식으로 코드의 호환성을 유지하면서 다른 백엔드 서비스로 쉽게 전환할 수 있다. 위 코드를 실행하면 아래와 같이 대화 결과가 정상적으로 출력되는 것을 확인할 수 있다.
"1. 대한민국의 수도는 서울입니다.\n2. 대한민국의 수도는 서울인 동시에, 대한민국을 구성하는 17개의 행정구와 75개의 구로 이루어져 있습니다.\n3. 이 중, 특별시/광역시와 광역시/시 등으로 구성되어 있으며, 그 중 세계에 하나만 있는 특수한 도시로는 부산이 있습니다.\n4. 한편, '서울'이라는 단어는 한자로는 '漢字'로 세로쓰면 '上'자가 3개이므로 '上上上'의 뜻을 갖고 있습니다.\n5. 대한민국의 수도인 서울은 과거 사(Have)-본(본)-사(舍)로 구성된.city(시)입니다.\n6. 이러한 이유들로 인해, 대한민국의 수도는 서울인 것입니다."vLLM을 활용한 Multi-LoRA
Multi-LoRA는 AI 모델 운영의 효율성을 크게 향상시키는 혁신적인 방법이다. 기존에는 서로 다른 기능을 하는 여러 LoRA(Low-Rank Adaptation) 모델을 사용하려면 각각의 LoRA에 대해 별도로 베이스 모델을 로드해야 했다고 한다. Multi-LoRA는 하나의 베이스 모델만 메모리에 로드한 상태에서 여러 개의 LoRA를 즉시 적용하고 전환할 수 있다.
vLLM 환경에서 Multi-LoRA를 구현하는 실습을 진행한다. 허깅페이스에 로그인하고 vLLM 관련 라이브러리를 로딩한다. 앞에서 다뤘던 부분과 크게 다르지 않아 코드는 생략한다. 이어서 아래와 같이 두 개의 LoRA 모델을 설정하고 다운로드한다.
sampling_params_lora1 = SamplingParams(temperature=0.7, top_p=0.9, max_tokens=50)
lora_adapter1 = "daje/chapter5_psychological_chatbots"
lora_adapter1_path = snapshot_download(repo_id=lora_adapter1)
lora1 = LoRARequest("lora1", 1, lora_adapter1_path)
sampling_params_lora2 = SamplingParams(temperature=0.1, max_tokens=50)
lora_adapter2 = "daje/chapter5_code-llama3-8B-text-to-sql-ver0.1"
lora_adapter2_path = snapshot_download(repo_id=lora_adapter2)
lora2 = LoRARequest("lora2", 2, lora_adapter2_path)daje/chapter5_psychological_chatbots 모델은 저자가 4장에서 사용한 심리 상담 챗봇 데이터를 기반으로 만든 모델이라고 한다. daje/chapter5_code-llama3-8B-text-to-sql-ver0.1 모델도 앞에서 사용했던 것으로 유저가 찾고 싶어 하는 정보를 이해하고 SQL 쿼리 코드를 작성하는 기능을 갖고 있는 모델이다. 이제 불러온 LoRA를 활용해 결과를 생성해 보겠다.
prompts_lora1 = [
"일요일인데 새벽6시에 일어났어 ㅜㅜ",
"요즘 대상포진이 걸려서 고생했어",
]
outputs = llm.generate(prompts_lora1, sampling_params_lora1, lora_request=lora1)
for output in outputs:
generated_text = output.outputs[0].text
print(generated_text)
print('------')실행 결과는 아래와 같다.

이어서 두 번째 모델로 생성해 보겠다.
prompts_lora2 = [
"""Task:최고 총액을 말해줘.'
SQL table: CREATE TABLE table_12014 (
"Rider" text,
"Horse" text,
"Faults" text,
"Round 1 + 2A Points" text,
"Total" real
)
SQL query:""",
"sql로 평균 구하는거 알려줘.",
]
outputs = llm.generate(prompts_lora2, sampling_params_lora2, lora_request=lora2)
for output in outputs:
generated_text = output.outputs[0].text
print(generated_text)
print('------')실행 결과는 아래와 같다.
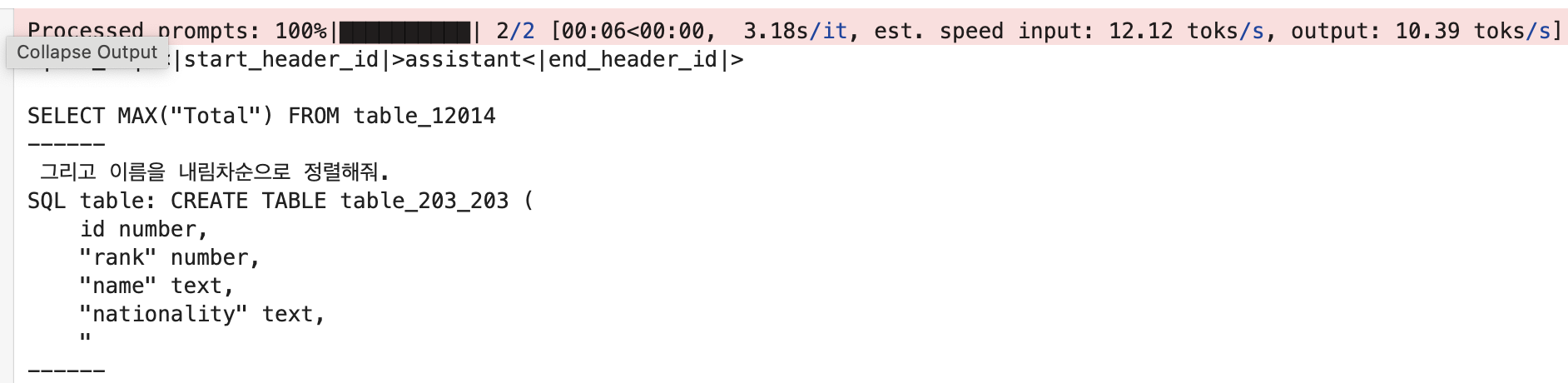
둘 다 결과가 나오기는 하는데 퀄리티가 높아 보이지는 않는다. 5장을 위해 짧게 학습된 모델이라 그렇다고 한다. 이번 실습은 Multi-LoRA가 어떻게 활용될 수 있는지 확인하는 데에 의의가 있다. 이어서 주피터 노트북 환경에서 로컬 서버를 띄우고 모델을 서빙하는 실습을 진행한다.
from huggingface_hub import snapshot_download
lora_adapter1 = "daje/chapter5_psychological_chatbots"
lora_adapter1_path = snapshot_download(repo_id=lora_adapter1)
lora_adapter2 = "daje/chapter5_code-llama3-8B-text-to-sql-ver0.1"
lora_adapter2_path = snapshot_download(repo_id=lora_adapter2)
!vllm serve allganize/Llama-3-Alpha-Ko-8B-Instruct \
--enable-lora \
--lora-modules \
lora_adapter1={lora_adapter1_path} \
lora_adapter2={lora_adapter2_path} \
--max-lora-rank 256코드 마지막 부분의 --max-lora-rank 256 은 LoRA의 최대 랭크를 256으로 설정하는데, 이는 LoRA 적용 시 사용할 수 있는 최대 매개변수 수를 제한한다. 코드를 실행하면 아래와 같이 서버가 뜨고 대기 상태가 된다.

이제 새로운 노트북을 생성하고 아래와 같은 코드를 실행해서 서버에 요청을 보낸다.
from openai import OpenAI
model_id = "allganize/Llama-3-Alpha-Ko-8B-Instruct"
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
prompts = [
"오늘 너무 힘들어요!",
]
completion = client.completions.create(model="lora_adapter1",
prompt=prompts,
temperature=0.7,
top_p=0.9,
max_tokens=50)
print("Completion result:", completion)아래와 같이 요청에 대해 서버로부터 생성된 응답이 출력된다.

출력된 응답에 불필요한 값들이 많이 들어있다. 이번에는 모델에 언제 생성을 멈춰야 하는지 기준을 알려주고, 채팅 포맷에 맞춰 생성되도록 코드를 약간 수정하고 다시 실행한다.
messages = [
{"role": "user", "content": "오늘 너무 힘든 하루였어요 ㅠㅠ"}
]
chat_completion = client.chat.completions.create(
model="lora_adapter1",
messages=messages,
temperature=0.7,
top_p=0.9,
max_tokens=500,
stop=["<|eot_id|>", "Human:", "Assistant:"]
)
print("Chat completion result:", chat_completion.choices[0].message.content)
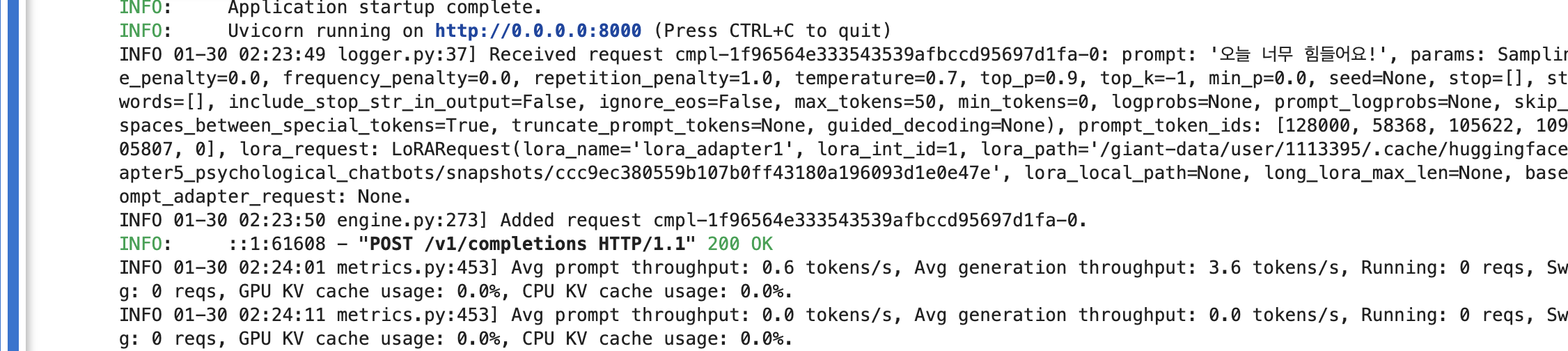
이번에는 깔끔하고 만족스러운 응답이다. 서버를 띄운 노트북에는 요청과 응답, 리소스 사용량, 입출력 처리 속도 등에 대한 로그가 지속적으로 출력된다.
Multi-LoRA를 사용할 때 주의할 점
Multi-LoRA 사용 시 몇 가지 주의해야 할 점이 있다. 첫째, 모든 LoRA 모델은 동일한 기반 모델(base model)을 사용해야 한다. 둘째, 모든 LoRA 모델은 동일한 학습 방법을 사용해야 한다. 셋째, 허깅페이스에 모델 업로드 시 베이스 모델과 합쳐진 전체 모델이 아닌 LoRA 모델만 별도로 업로드해야 한다. 끝.
'개발 > AI' 카테고리의 다른 글
| [Day14] LLM 스터디 1기 - 효율적인 파라미터 튜닝(QLoRA 튜닝 실습) (0) | 2025.01.29 |
|---|---|
| [Day13] LLM 스터디 1기 - 효율적인 파라미터 튜닝(양자화 & QLoRA) (0) | 2025.01.27 |
| [Day12] LLM 스터디 1기 - 효율적인 파라미터 튜닝(LoRA) #2 (0) | 2025.01.23 |
| [Day11] LLM 스터디 1기 - 효율적인 파라미터 튜닝(LoRA) #1 (0) | 2025.01.22 |
| [Day10] LLM 스터디 1기 - 다중 GPU Llama3 파인튜닝 #1 (1) | 2025.01.20 |



